Tutorials
Instructions on How to use HPC and CHTC at UW-Madison
-
Command Lines Basics:
- HPC at UW-Madison: It runs for a maximum of 7 days, equivalent to a large computer.
- HTC at UW-Madison: It runs for a maximum of 3 days and can run multiple jobs in parallel, then combine the results together.
- How to determine if a task is suitable for running on HPC (a large computer where tasks can interact but also perform parallel computing) or HTC (multiple computers running together without task interaction).
- Terminal (Mac) & Ubuntu (Win) connect to HPC:
ssh NetID@hpclogin3.chtc.wisc.edu - Terminal (Mac) & Ubuntu (Win) connect to HTC:
ssh NetID@submit3.chtc.wisc.edu - Abtain the path of files:
readlink -f file.txt(Linux);bash-3.2$ pwd file.txt(bash) (Link). - Navigating directories:
cd(Link). - Display a list of files:
ls(Link). - Display the contents of one or more files:
cat(short for: concatenate) is used to concatenate files and display their contents on the standard output device (Link). echo “A B B A C C” > example.txtis used to write the string "A B B A C C" to a new file called "example.txt".python3 wc.py example.txtis to run the Python scriptwc.pywith the example.txt file as input data in the terminal.- Transfer files:
- Local desktop %
scp NetID@hpclogin3.chtc.wisc.edu:/home/sample.zip .transfer data from HPC/HTC to local PC. scp test.zip NetID@hpclogin3.chtc.wisc.edu:/home/transfer data from local PC to HPC.- Local desktop %
scp -r NetID@hpclogin3.chtc.wisc.edu:/home/temp /Volumes/datatransfer the whole directory data from HPC/HTC to local PC.
- Local desktop %
- Compressing files:
zip -r example.zip exampleCompressing files.unzip -l name.zipis used to list the files and directories inside a ZIP archive without actually extracting them.unzip example.zipTo unzip the file "exaplem.zip" and extract its contents into the current folder.tar -cvf data_folder/data.tar data_folder/compress data.tar -xzf data_folder/data.tar.gz -C data_folder/uzip data.tar -xvf data_folder/data.tar -C data_folder/unzip data.
g++ xtem423e4.cpp -o temmodelCompile terrestrial ecosystem model, we have the g++ compiler installed and that the source code file xtem423e4.cpp is in the current directory. It compiles the source code and generates an executable named temmodel using the -o flag../temmodel tem4.para tem4.logrun TEM, temmodel executable file in the current directory, and you want to run it with the input parameters file tem4.para and output log file tem4.log.wc -l filenameis used to count the number of lines in a file.- HTC:
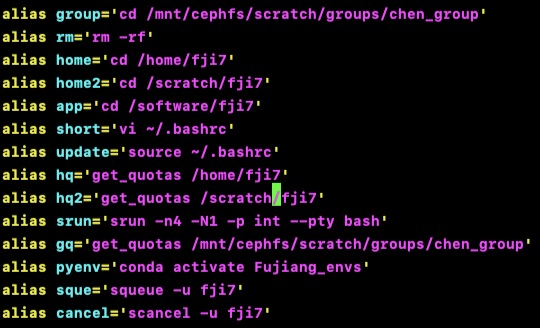
condor_qis used to query and manage jobs in the HTCondor system. It provides information about the status of submitted jobs, such as their ID, current status (queued, running, completed, etc.), and resource usage;condor_statusis used to monitor and view the status of computers (also referred to as resources or execution hosts) within the HTCondor system. It provides information about the availability, load, and other attributes of the computers registered with HTCondor. grep mkclds *is used to search for the pattern "mkclds" in all files in the current directory.:q!Quit vi without saving changes.:wq!Save changes and exit vi forcefully.module availis to view the available modules on your systemmakeusing gfortran compile, navigate to the directory containing the Makefile and the Fortran source files and run the make command. This will execute the build rule specified in the Makefile, compiling the program using gfortran and generating the executable.- How to create alias on local PC and HPC.
- HPC and HTC:
vi ~/.bashrcsetting alias.source ~/.bashrcupdate alias after setting it.Examples of Alias.
- Login to HPC without password:
- Step 1: passwordless login: Link.
- Step 2:
scp ~/.ssh/id_rsa.pub ssh NetID@hpclogin3.chtc.wisc.edu:/home/NetID/.ssh/ - Step 3:
scp ~/.ssh/id_rsa.pub ssh NetID@submit3.chtc.wisc.edu:/home/NetID/.ssh/ - Step 4:
nano ~/.zshrcsetting alias (Mac, local). - Step 5:
source ~/.zshrcupdate alias (Mac, local).
- HPC and HTC:
- Connect VS code and HPC: Link.
-
Run Python Programs on HPC:
- Install Miniconda on software directory (Link):
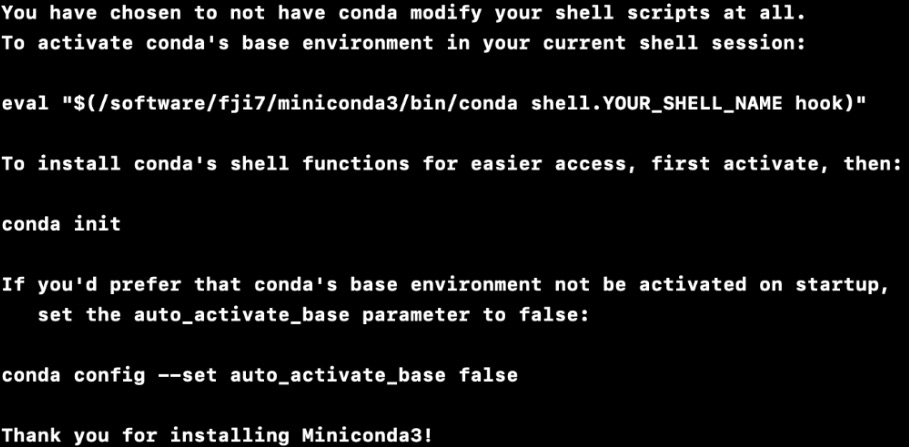
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shsh Miniconda3-latest-Linux-x86_64.shinstall Miniconda on the software directory.Miniconda installation. - After installation, active base environment:
eval "$(/software/fji7/miniconda3/bin/conda shell.bash hook)"(Link).
- View how many environments are already built:
conda env list - Build or delete an environment for conda:
conda create -n envs_name python=x.x,conda env remove --name envs_name - Activate/ deactivate the
environment:
conda activate envs_name,conda deactivate - Install packages you need:
conda install packages;pip install packages - Before submitting jobs, we can apply a small compute resource to debug on
HPC:
srun -n4 -N1 -p int --pty bash(Link1, Link2). - Terminal run python file:
python name.pyorrunipy name.ipynb - Submit jobs: (Link1,
Link2):
sbatch tasks_upload.sh(below shows the template oftasks_upload.sh).#!/bin/bash # Sets the name of the job. This is typically used for identification purposes.SBATCH --job-name=PLSR_modeling # Requests one compute node for the jobSBATCH --nodes=1 # 10 tasks (or processes) running per node. This parameter is relevant for parallel computing.SBATCH --ntasks-per-node=1 # Define the number of CPUs allocated per taskSBATCH --cpus-per-task=1 # maximum memory for the whole job is 128GBSBATCH --mem=128gb # specifies the maximum runtime for the job as 24 hoursSBATCH --time=24:00:00 # the log fileSBATCH --output=PLSR_modeling.out # Activate the conda environmentsource /software/fji7/miniconda3/bin/activate /software/fji7/miniconda3/envs/Fujiang_envs # Run the scriptpython /home/fji7/HPC_test/Spatial_PFTs.py - In a typical computing system, there is a hierarchical relationship between nodes, cores, and
CPUs:
- Node: A node refers to a physical computing unit or a server in a distributed computing system. It can consist of one or more CPUs.
- Core: A core is an individual processing unit within a CPU. Modern CPUs often have multiple cores, which allows for parallel processing. Each core can execute instructions independently.
- CPU: The Central Processing Unit (CPU) is the main processing unit of a computer. It consists of one or more cores. Each CPU can handle multiple tasks concurrently by utilizing its cores.
- It's important to note that while a CPU can have multiple cores, each core can execute its own thread or process independently. Therefore, a CPU with multiple cores can handle multiple programs or processes simultaneously. This is known as parallel processing, where different cores execute different instructions concurrently, improving overall performance and multitasking capabilities.
- A node contains one or more CPUs, each CPU can have multiple cores, and each core can handle a
separate program or process concurrently. This hierarchical structure allows for efficient
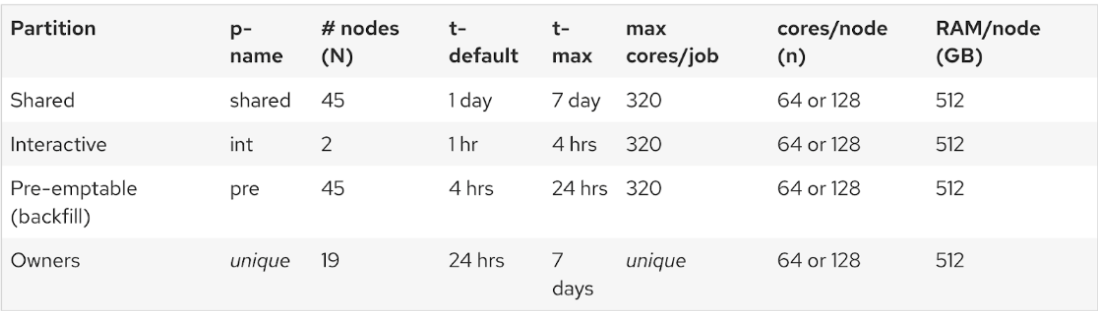
multitasking and parallel processing in modern computing systems (below shows the resources
availability at UW-Madison HPC).
Computing resources availability at UW-Madison.
- Install Miniconda on software directory (Link):